


Abstract
A psychometric scale reports experiences in terms of items/sentences rated by individuals. We investigate whether psychometric item ratings reflect semantic/syntactic associations between concepts in items. To this aim, we introduce semantic loadings as a semantic counterpart of psychometric factors, i.e. clusters of items obtained by correlations between item ratings. Semantic loadings quantify how clusters of semantically related concepts, as expressed in the texts of items, are allocated across psychometric factors as identified by ratings. As a case study, we focus on 39775 individual responses to the Depression Anxiety and Stress Scale (DASS) with 42 items on a 4-point Likert scale. To identify communities of semantically related concepts, we exploit the cognitive network framework of Textual Forma Mentis Networks (TFMNs), which reconstruct semantic/syntactic links encoded in the texts of items (e.g. "feel" and "sad" in the item "I usually feel sad"). To identify factors we compare eigenvector-based exploratory analysis with Graph Exploratory Analysis (EGA), which can both cluster items (and their texts) according to user ratings. We find that EGA is better at reconstructing the psychological organisation of DASS along the dimensions of anxiety, stress and depression. Following dual coding theory and the Deep Lexical Hypothesis, we posit that the act of reading items activates interconnected concepts and this influences user ratings and their expressed psychological constructs. Our results show a quantitative match: TFMN-based semantic loadings can identify specific aspects of emotional dysregulation, emotional exhaustion, physical distress and tension states of EGA-based psychometric factors, in non-random ways (up to p < 0.001). We discuss our results in view of relevant mental distress literature, psychometric scale designing and links with episodic and semantic memories.
Editor Curated
Key Takeaways
- This study introduces semantic loadings, a novel metric that connects the semantic relationships between words in a psychometric scale (like the DASS-21 for depression, anxiety, and stress) to the statistical structure of the scale's factors.
- The research demonstrates that these semantic loadings can account for a significant amount of variance in traditional psychometric factor loadings, showing that the meaning of items is strongly linked to how they cluster statistically.
- By bridging cognitive network science with network psychometrics, this approach offers a new way to understand the formation of psychological constructs, with semantic loadings outperforming purely psychometric methods in predicting the DASS-21 factor structure.
Keywords:



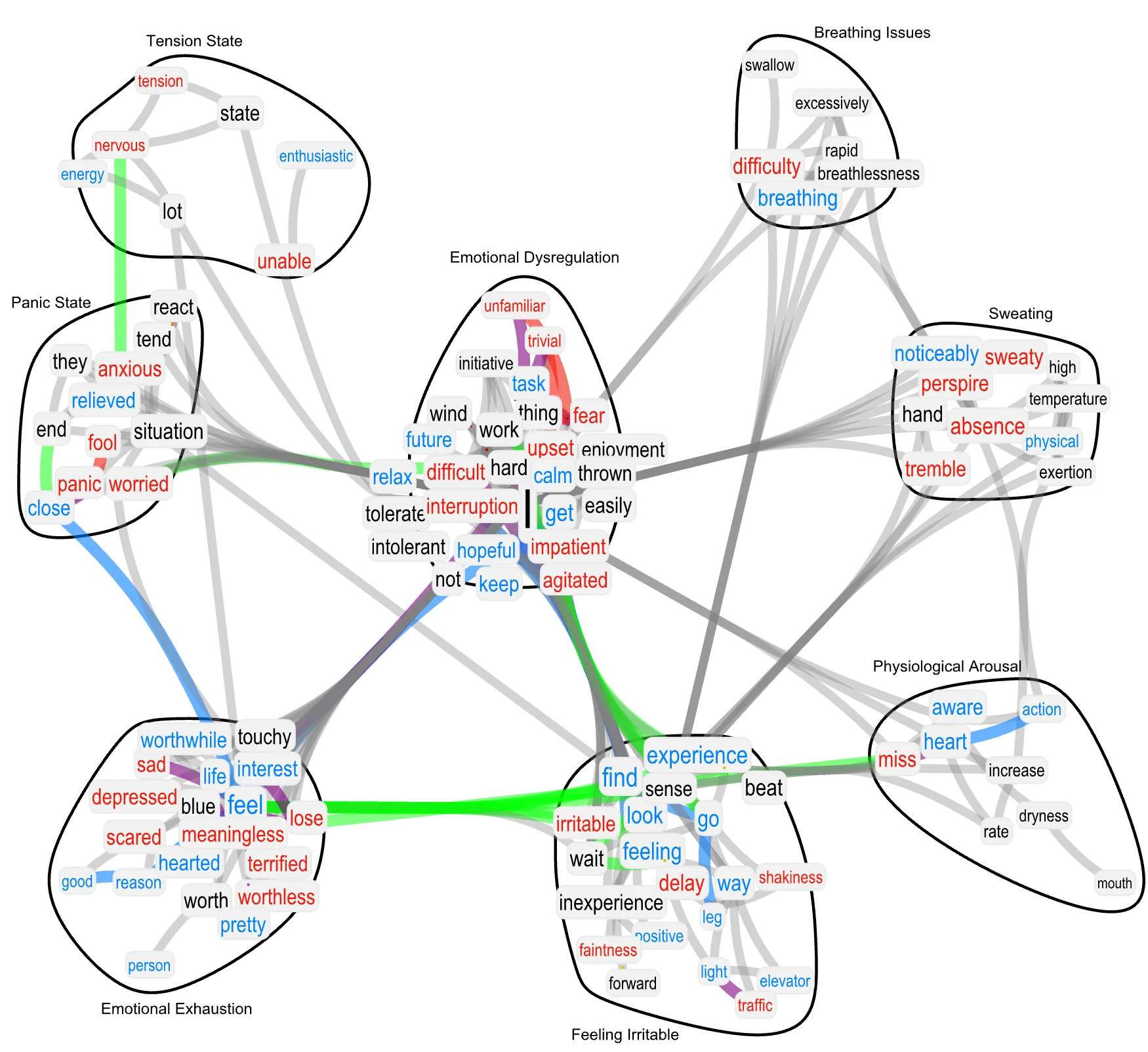
![Semantic Loadings Obtained as the Overlap (Jaccard index) Between the Psychometric Semantic Factors and the TFMN Semantic Factors. Each semantic loading was compared against numerical simulations randomising psychometric semantic factors. Statistically significant loadings were highlighted with one (p-value ∈].1, .01]), two (p-value <∈].01, .001]) or three (p-value < .001) stars.](https://advances.in/psychology/wp-content/uploads/figure4-2.webp)









